- 雲端運算簡介
- Hadoop簡介
- Hadoop 安裝與設定解析
- Hadoop Distributed File System 簡介 (HDFS)
- MapReduce 介紹
- 快速佈建 Hadoop 叢集 (Cluster)
在進行以下的討論之前,先來確定一些基本假設:
- Hadoop 架構的設計目標是要能夠以低成本且有效率的方式處理 PB 等級的資料量
- HDFS 是一個可動態擴充的分散式檔案系統,在 Hadoop 架構中一份資料預設會有 3 份副本(Replication)
這是整天的課程中我最感興趣的,因為這代表一種思維的轉變。傳統在設計系統時,最常使用的就是三層式架構 (Three-tier architecture),如下圖:
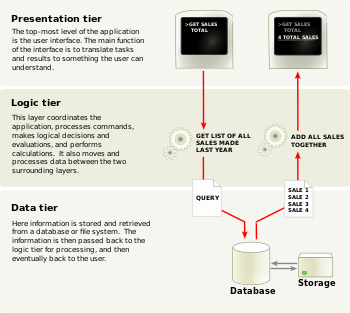
(資料來源:Wikipedia - Multitier architecture)
就算在佈署時把 Presentation 和 Logic Tier 放在同一台 Server (在小型的 site 也許可以),Data Tier 一定會放到另一台 Server 上面去。在 Logic tier 執行系統核心的運算前,必須將待運算的資料從 Data Tier (DB Server) 搬運到 Logic Tier (AP Server) 進行運算,也就是以資料就運算,負責執行運算的程式檔案本身是不移動的(固定佈署在 Logic Tier 上),執行運算所需的資料則從其他的機器(或者 cluster) 搬運到程式所在的機器上。
在這樣的傳統架構中,資料的傳輸情況如下:
- 在網路上傳輸待運算的資料(大量):Data Tier –> Logic Tier
- 程式要執行時,從 Disk 複製到記憶體中(少量):Logic Tier Disk –> Logic Tier Memory
- 以檔案大小而言,要執行的程式檔案是很小的 (e.g., .exe/.dll),但待運算的資料量是非常大的 (Hadoop 的 target 是 PB 等級的資料)。
- AP Server 必須要先從 DB Server 拿到資料才能開始運算,在這段網路傳輸時間內資料只是單純的被搬運而已,並沒有被計算,因此對運算任務而言,網路傳輸時間是完全的 overhead。
- 當待運算的資料量越來越大,例如達到 PB 等級時,消耗在網路傳輸的時間會大幅增加,因此需要佈建超高速的網路 (e.g., Fiber Channel, FC),相較於成本較低且技術已經很成熟的 GE 網路來講,又要花費更高的成本。
 (資料來源:Hadoop簡介 P.21)
(資料來源:Hadoop簡介 P.21)以下是 Hadoop 中各角色的簡單說明 (參考 Hadoop簡介 P.19~20)。首先,負責儲存資料的單元可區分為:
- Namenode: 擔任 master 的角色(只能有一個),管理檔案的讀寫,以及 Replication (副本) 的策略
- Datanodes: 擔任 slave 的角色(可以有多個),接受 Namenode 的指揮,實際儲存資料的 Replication (副本),並執行檔案的讀/寫,將資料提供給 Tasktracker 進行運算
- Jobtracker: 擔任 master 的角色(只能有一個),也就是工頭,接受使用者 (Client,通常是另一個程式,不一定是指真實的人) 發起的工作,並進行工作排程 (Job Scheduling),將工作 (Job) 分派給 Tasktrackers 執行,並彙整 Tasktrackers 的計算結果後,將最終結果回傳給使用者
- Tasktrackers: 擔任 slave 的角色(可以有多個),也就是工人,接受 Jobtracker 的工作指派,跟 Datanodes 要求待運算的資料,執行實際的運算後,將結果回傳給 Jobtracker 彙整
![pub[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjhqJojkwc0lMFkLiZBENcOssERRWjoyBvnD_LKrBhaXOEiHRqeXWo4K4XRNYNPIKh-DyXV4kEAJJlpbru6U9iLq63GKIFOfSUOKeY3ybZABcorqNprDKkCtS_doE_EJPSLkoCi6f1dy-0/s1600-h/pub%5B1%5D%5B3%5D.png "pub[1]")
(資料來源:我自己用 Google Doc 畫滴)
(註:Job 執行完畢以後,每個 TaskTracker 會將計算結果回傳給 JobTracker 彙整,而後再由 JobTracker 回傳給 Client)
(2010-04-20 補充:石頭閒語有篇文章有個類似的圖,參考這裡)
由上圖可以看出,當一個運算任務 (Job) 要被執行時,JobTracker 會將要執行的程式(相較之下檔案很小)傳送到資料所在的位置(Datanodes),而後待執行的運算便就地在 Datanode 上由 Tasktracker 完成,這就是以運算就資料,與其將很大量的資料到程式透過網路搬運到程式所在的機器上,不如先搞清楚資料在哪裡,接下來把小小的程式複製到資料所在的位置去執行。在這樣的架構中,資料的傳輸情況如下:
- 在(GE)網路上傳輸要執行的程式(少量資料):Client –> Jobtracker –> Datanodes
- 在 Datanodes 本機上傳輸待運算的資料(大量資料):Datanodes Disks –> Datanodes memory,完全不需要透過網路!速度肯定快很多!
通常原本很大量的資料經過運算以後,產生的資料量會比原來的資料小很多很多,因此在 JobTracker 與 TaskTracker 之間的資料傳輸就不會消耗太多的網路頻寬(這和 WCG 的特性是一樣的)。上課時老師也提到,根據估計,目前每年全世界產生的資料量已經大於全世界硬碟的總容量,因此未來如何能夠快速的處理大量原始資料,而僅儲存運算之後所得到的有用資訊,就是各大未來企業競爭的重點(目前已經是 Google、Yahoo 等每天需要分析超大量 web server log 的公司所面對的挑戰),目前看來 Hadoop 這個經過實戰(Yahoo)驗證的架構是很有希望的技術。
以上就是我認為這次課程最重要的觀念啦!
補充
雲端運算核心技術 Hadoop 與 MapReduce 概念班內容包括:
- 雲端運算簡介:重點在投影片 P.3~P.6<雲端運算的定義及精髓>、P.19 <全球資料爆炸的預估量>、P.22~P.25<大量資料運算的教訓與未來趨勢>、P.40 <What we learn today?>
- Hadoop簡介:重點在投影片 P.4~P.6<Hadoop基礎概念>、P.14 <Hadoop 與 google 的對應>、P.18<名詞,這一段非常重要!是未來討論的基礎>、P.19~21 <Hadoop 的 4 種身份以及最常見的佈署方式>
- Hadoop 安裝與設定解析:這個部份等到要實作的時候再看就好
- Hadoop Distributed File System 簡介 (HDFS):這份投影片每一張都很重要!其中我覺得 P.5 <設計目標(2)> 中的「在地運算」非常有意思,下一段會詳細說明。
- MapReduce 介紹:again, 這份投影片每一張都很重要!P.2~P.9 是 MapReduce 演算法的介紹,P.10~16 有很多應用 MapReduce 演算法的實例
- 快速佈建 Hadoop 叢集:當企鵝龍遇上小飛象 DRBL-Hadoop (投影片),這是利用國網中心開發的快速、大量佈署技術(企鵝龍) 來快速佈建 Hadoop cluster 的作法,一樣是等到實作再看就可以了。(不過老師也提到,利用這種技術可以幫助人力吃緊的中小學老師快速有效的管理電腦教室,並且替學校節省很多成本,這也是國網中心的重要任務之一。)
- 國網中心
- NCHC Cloud Computing Research Group: 有 Project News 和 Training Course
- 雲端運算核心技術 Hadoop 與 MapReduce 概念班: 我這次上的課
- Wikipedia
- 新聞
- [2009-06-24] iThome-Yahoo! 推出 Hadoop 雲端發行套件
- [2009-11-17] iThome-開發 Hadoop 雲端應用沒那麼難
- [2009-12-09] iThome-日本雲端伺服器明年1月搶先上市
-
-




{kind=link}
2 則留言:
雲端運算充其量只是co-location與軟硬體租賃的新行銷名詞罷了! 最大的好處就是可以處理peak的運算量!
另外3-tier架構中, 若需要大量資料於Data tier搬移Logic tier時, 其實是會考量直接運用Data Tier中的預存程序計算出中間結果, 當然這有trade-off! 每當我看到用logic tier作大量運算的code時, 其實覺得又好氣又好笑!!!!
三層式架構推出, 當初是主打免安裝, 減輕MIS人員loading, 並不是主打效能, Logic tier中大多執行script language, 比兩層式的Native Code慢很多很多的!
甚麼需求要送到雲上去, 甚麼維持現有架構, 其實是各有各的考量!
Hi, 我很贊同你說的「甚麼需求要送到雲上去, 甚麼維持現有架構, 其實是各有各的考量! 」。就 Hadoop & MapReduce 的應用來講,若資料量沒有大到 PB 以上,是不會明顯感受到好處的。
但是關於「若需要大量資料於Data tier搬移Logic tier時, 其實是會考量直接運用Data Tier中的預存程序計算出中間結果」這一點,跟 Hadoop 這種分散式計算的架構還是有很大的差異。
當要計算的資料量達到 PB 這種等級,若仍繼續用傳統的循序方式作集中式的運算勢必會遇到很大的瓶頸,換個角度來說就是 scale up (集中式運算) 和 sacle out (分散式運算)的差異,透過 Google 和 Yahoo 近幾年的實際應用,可以知道如 Hadoop 這樣的分散式運算架構的確可以解決這個問題 (起碼在運算/儲存能力超強的量子電腦被實作出來且大量應用之前是如此)。
最近雲端運算的確有被濫用的狀況,導致很多時候讓我們感覺這只是廠商提出的另一個新的行銷名詞,但仔細研究其技術的內涵,還是可以與舊有的技術做出明顯的區分的。
能夠把一些既有的技術結合在一起,提出一個完整的軟硬體架構來解決計算超龐大資料量的挑戰,我覺得是很有價值的~
張貼留言