前陣子整理了之前上課的筆記:以運算就資料(在地運算) vs. 以資料就運算 (雲端運算核心技術 Hadoop & MapReduce 概念班上課心得),那次課程的內容包括:
- 雲端運算簡介
- Hadoop簡介
- Hadoop 安裝與設定解析
- Hadoop Distributed File System 簡介 (HDFS)
- MapReduce 介紹
- 快速佈建 Hadoop 叢集 (Cluster)
接下來再補充一些心得。
何謂雲端運算?
這是個最近很熱門的話題,講義裡面(P.3)濃縮成一句話是「能夠隨時隨地使用任何裝置存取各種服務」(但我覺得這講得太模糊了,甚至跟 Web 1.0 or U 化都無法區別)。講義中比較精確的定義是參考 NIST (word 檔,重點就是 543, 講義 P.4, 5大基礎特徵,4個佈署模型,3個服務模式)。另外也看到 Gartner 的定義,以及Twenty-One experts defining Cloud Computing等等。
如果講得更技術一點:雲端運算是一種新的運算方式,可讓任何連網裝置透過網路(基本上是 Internet),使用者根據(可能會劇烈變動的)需求存取所需的運算資源(CPU Power / Storage),最後根據使用量付費 (pay-as-you-go)。我覺得使用者能夠 on-demand 的、基本上無上限的(只要付的出錢來)、在短時間內(數十秒到幾分鐘)擴充所需的運算資源,是雲端運算最重要的特性,因為這是以往的架構所做不到的。這個定義的重點除了 on-demand 的動態擴充能力之外,還包括:運算資源透過網路存取、根據使用量付費。假如像某些專家所說,只要把資料/服務放到網路上遠端的電腦,從此可以讓任何連網裝置透過網路存取,就叫做雲端的話,那所有的 Web-based 系統都可以叫做雲端運算囉?這根本就是鬼扯。難道有人可以在 5 分鐘內把 SVN 系統從 1 台變成 50 台嗎?保證辦不到的嘛!而且現在所有的系統都必須透過網路溝通(例如三層式架構),就算不開放公開的 Internet 存取,企業內部也會建構 Intranet,所以透過網路存取這點就沒什麼好稀奇的了。
至於根據使用量付費,從技術的觀點來看,我覺得也不是雲端運算最重要的特性(雖然說這也不太容易做,系統必須在盡可能不干擾使用者使用服務的狀況下,詳盡的記錄使用情形,並且提供一個 web-based 的 dashboard 讓使用者隨時隨地掌握服務的運作/使用狀況),不過上課的時候老師有提到,未來如果這種依使用量付費的商業模式越來越成熟,可能會出現一種新的專業(顧問):雲端精算師,主要工作是要幫客戶規劃如何使用雲端服務,能夠以最少的成本滿足運算的需求 (例如要用怎樣的 OS/AP 組合來執行運算任務,不是透過網路把精算工作丟給遠端的精算人員唷揪咪^.<)。
要提供 on-demand 動態擴充的運算能力,除了需要靠虛擬化技術以外,也必須建構在分散式運算 (Hadoop) 以及分散式檔案系統 (HDFS) 之上。如果僅能透過虛擬化技術作到快速的新增虛擬機器(VM),並且設定好相關的網路組態(我覺得這樣已經很厲害了),但是資料無法有效的存放到分散式的檔案系統中,以提昇存取效率,對於超大量資料 (PB等級) 的運算是沒有幫助的。而若只是將資料由集中改為分散存放,程式是不會自動變成以分散式的方式去執行的,程式架構必須重新設計(也就是利用 MapReduce 演算法改寫),這就和單執行緒程式如果不經過調整,只是把 CPU 從單核換成多核,程式也不會自動變成多執行緒,是一樣的道理。
在 Gartner 的文章裡面有一段講得很好,過去講 Client/Server 架構的精髓就是:使用者要的是一種「不是放在 mainframe 上面跑」的系統;而雲端運算的精髓則是:使用者付費想要買的是服務以及服務所產生的結果,而不是運算的基礎設施(也就是不要再自己買機器、建機房了)。我認為這是從 PaaS Provider / SaaS Provider / SaaS Provider 的客戶等人的角度來看的,也就是把建構、維運基礎設施的成本轉嫁到 IaaS Provider 身上,而對 IaaS Provider 來講,則可以提高機器的利用率(multi-tenant),並且可收割位於長尾末端的客戶的運算需求(也就是無力自建機房,或者需要面對劇烈變動的需求的小型企業)。(但我一直在想,雲端運算真的有完全解決 IaaS Provider 所面臨的效能不足<under-utilization> 和效能過剩<over-utilization>問題嗎?感覺為了避免效能不足的問題,很容易就會造成效能過剩的現象。)
下一段補充 HDFS 分散式檔案系統的觀念。
以機率的觀點出發,將資料平均分散儲存在HDFS的成員(Datanode)中,以提高存取效率
前情提要:存入 HDFS 中的資料至少都會有3 份副本 (Replication),存放於(理想上位於不同機架<rack>)的機器上
把一個檔案存入 HDFS 時,HDFS (更精確的說是 Namenode) 會把檔案切割成固定大小的 block,而後將各 block 分散儲存到不同的 Datanodes 上,由於每個檔案的儲存都是跨實體機器的,因此 HDFS 可視為一個虛擬的分散式檔案系統 (傳統的檔案系統一樣會將檔案切割為 block,但都儲存到同一台實體機器的硬碟上),或者說是一個 Logical File System,而 Namenode 就負責扮演 Linux file system 中 inode 的角色,要知道組成某個檔案的所有 block 被儲存在哪些 Datanodes? 問 Namenode 就對了。
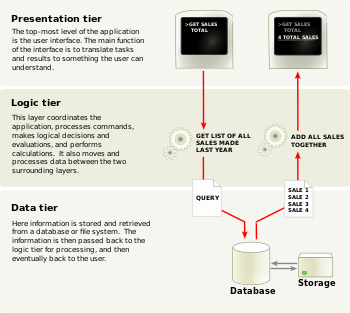
為了盡可能的提昇 HDFS 的存取效能(特別是讀取速度),HDFS 在儲存資料時必須將資料根據機率平均的分佈在組成 Hadoop cluster 的成員硬碟上(balancer的工作)。由於資料是平均分佈的,因此存取時就可以多管齊下,如下圖:

(資料來源:Apache.org - HDFS 架構設計)
當 Client 需要讀取 data 時,可以同時分別從五台 Server 各讀取一個 block,讀到以後再組合成完整的檔案即可,如此一來存取效率會比循序的從單一 Server 上依序讀取 block 1~5 來的快速許多,也可以降低每一台 Server 的 read lock 時間。
HDFS 其他的好處:
- 資料存取時間可以控制在一定的範圍內,硬碟的損耗也更平均,進一步減少檢修硬體的成本。
- 儲存於 HDFS 中的檔案大小可超過一顆實體硬碟的容量。由於 HDFS 是一個虛擬的分散式檔案系統,每個檔案的 block 本身就會跨實體機器儲存,因此自然不會受限於單一機器的硬碟大小了。例如雖然一個 Hadoop cluster 中的每台主機的硬碟都只有 500G,但這個 cluster 還是可以用來儲存 1TB/1PB 甚至更大的單一檔案,只要 cluster 內硬碟的總容量夠大就好。
- 整個HDFS系統是可以熱插拔的,當某一台 Server 的硬體壞掉時,HDFS 仍可正常運作(因為資料至少還會有另外 2 份副本),並且由於資料的副本數低於 Policy 所規範的量,HDFS 會立即開始找尋另外正常運做的 Server 來維持副本的數量。接下來的維修只要直接把那台 Server 關機,換一台新的 Server 上去加入服務就好。因此機房管理人員就不需要利用三更半夜進行硬體的修復了。
- 由於分散式架構可大幅提昇檔案的讀取速度,因此有雲端運算需求的企業(如 Google) 就不用再耗費鉅資購買高階的 Server,只要以一般的消費型機種就可以架構出高效能的運算平台 (以1台高階伺服器的價格可以輕易的買到10台以上的消費型機種,但1台高階伺服器的效能不會比10台消費型機種的總和來的強),如此可進一步降低 Data Center 的成本。
量少質精的資料不如超大量、品質還OK的資料
這是 Google 奉行不渝的原則,從以下兩篇文章可以略知一二:
- [The Official Google Blog] Helping computers understand language
We use many techniques to extract synonyms, that we've blogged about before. Our systems analyze petabytes of web documents and historical search data to build an intricate understanding of what words can mean in different contexts. - [Google Public Policy Blog] Making search better in Catalonia, Estonia, and everywhere else
In the past, language models were built from dictionaries by hand. But such systems are incomplete and don't reflect how people actually use language.
When building our models, we use billions of web documents and as much historical search data as we can, in order to have the most comprehensive understanding of language possible.
其他類似的例子還有很多很多。以 Google Translate 的作法為例,與其依靠極少數的專家來進行高品質的精確翻譯(成本很高),Google 選擇去蒐集大量的各種語文的對照文件(當然要有相當的品質,例如聯合國的文件),在有足夠大量文件的前提下,就可以提供很不錯的翻譯品質(隨著收集到的資料越來越多,自動翻譯的品質可以持續提昇),如此也才可以很迅速的根據使用者的需求,即時的將某個網頁從 A 語言翻譯為 B 語言。那麼要如何有效綠的儲存超大量的資料呢?當然是靠 HDFS 啦!超大量的資料蒐集完畢以後如何進行快速的分析呢?那就靠 MapReduce 囉!
其他感想
要打造一個包含軟硬體的完整架構真的很不容易,一旦架構建立以後,透過適當的講授就可以讓人在短短地幾小時內掌握此架構的重點,進而啟發出更廣泛的應用,如此可以快速的促成技術的進步,這是Google很大的貢獻。而Google把這個完整的架構以論文的形式發布,讓有心的人能夠很快的實作出來,真的是佛心來著呀!
關於雲端運算課程的心得,除了這兩篇文章以外,還有 key-value store 這個重要的軟體架構沒講到,希望在閱讀更多資料以後可以整理出一篇比較完整的心得。
另外還有從傳統的 IT 運算架構轉移到雲端運算的架構會遇到的困難,也是很值得深入討論的~
參考資料:
- 國網中心
- NCHC Cloud Computing Research Group: 有 Project News 和 Training Course
- 雲端運算核心技術 Hadoop 與 MapReduce 概念班: 我這次上的課
- Wikipedia

![pub[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjhqJojkwc0lMFkLiZBENcOssERRWjoyBvnD_LKrBhaXOEiHRqeXWo4K4XRNYNPIKh-DyXV4kEAJJlpbru6U9iLq63GKIFOfSUOKeY3ybZABcorqNprDKkCtS_doE_EJPSLkoCi6f1dy-0/s1600-h/pub%5B1%5D%5B3%5D.png "pub[1]")
![Joomla_extensions_types_thumb[1]](file:///C:/Users/TimLin/AppData/Local/Temp/WindowsLiveWriter415114243/supfiles7F510E/Joomla_extensions_types%5B3%5D.png "Joomla_extensions_types_thumb[1]")
![Joomla_Fabrik_IntroPage_thumb[1]](file:///C:/Users/TimLin/AppData/Local/Temp/WindowsLiveWriter415114243/supfiles7F510E/Joomla_Fabrik_IntroPage%5B3%5D.png "Joomla_Fabrik_IntroPage_thumb[1]")
![Joomla_Fabrik_DownloadPage_thumb[1]](file:///C:/Users/TimLin/AppData/Local/Temp/WindowsLiveWriter415114243/supfiles7F510E/Joomla_Fabrik_DownloadPage%5B3%5D.png "Joomla_Fabrik_DownloadPage_thumb[1]")


























{kind=link}